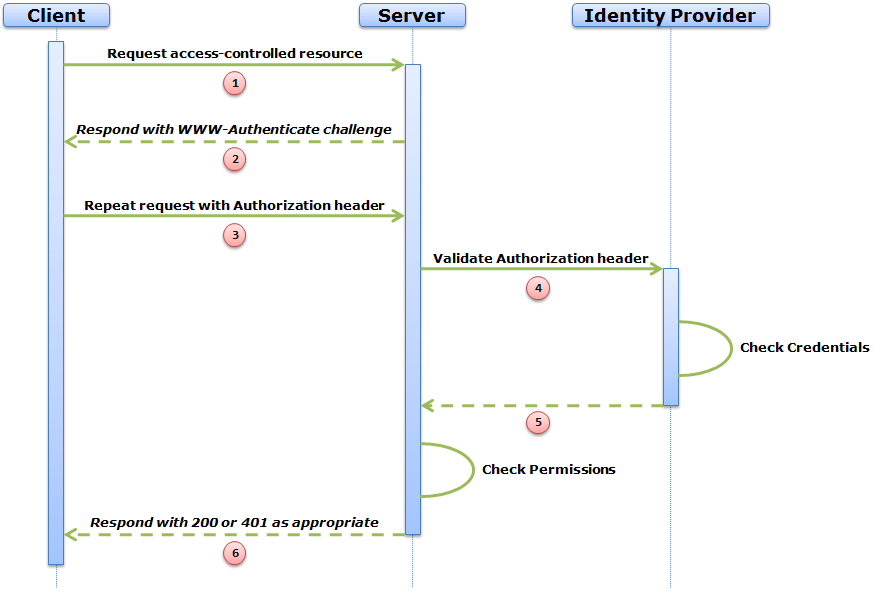
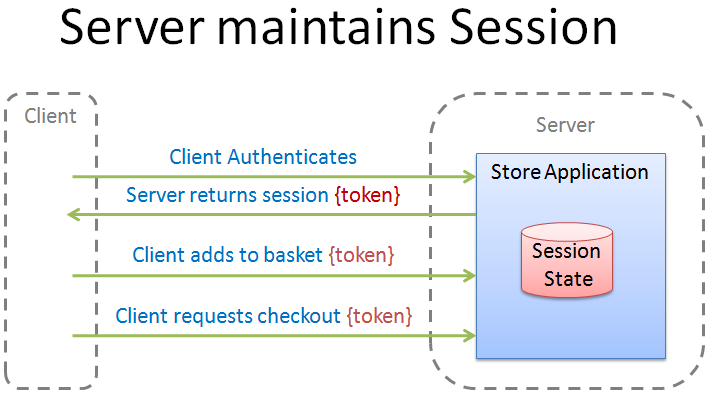
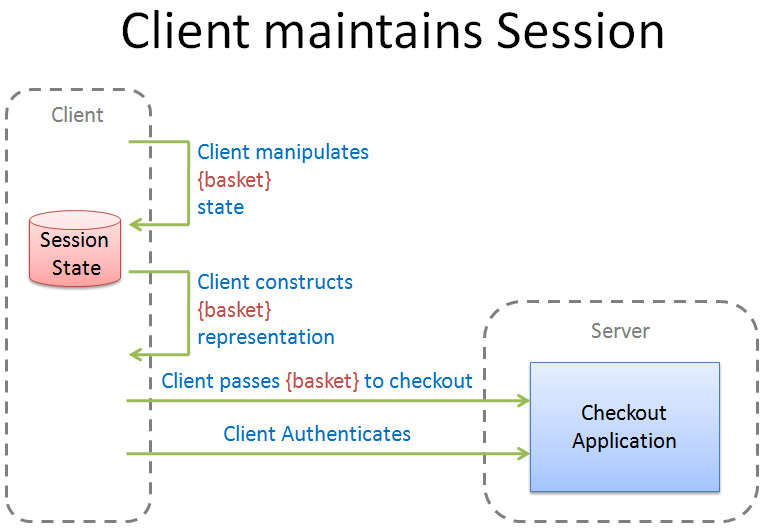
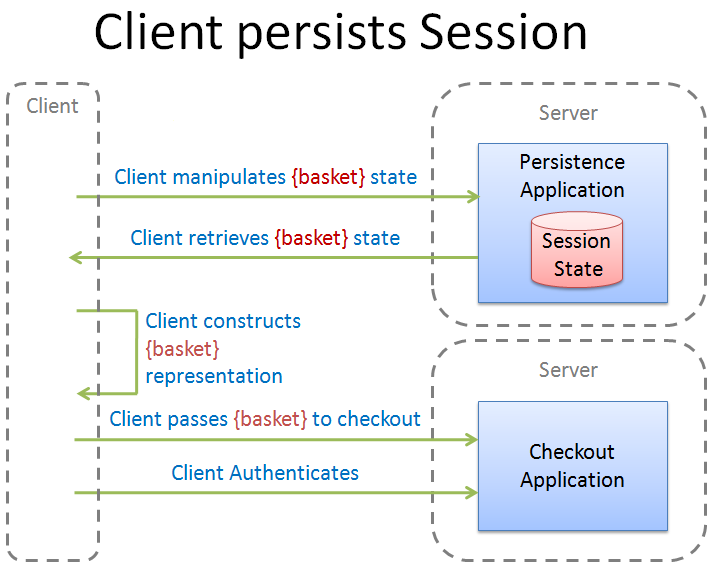
Time for a little reflection. Over the last year, I think that a great deal has been achieved in the Alt.Net community in the UK. We have had two conferences and Sebastian Lambla has now ran four Alt.Net Beers. These have stimulated healthy discussion in the community which I am very happy to see and we should continue to nurture.
Time for a little reflection. Over the last year, I think that a great deal has been achieved in the Alt.Net community in the UK. We have had two conferences and Sebastian Lambla has now ran four Alt.Net Beers. These have stimulated healthy discussion in the community which I am very happy to see and we should continue to nurture.
In the spirit of continual improvement, I have been thinking about how we can build on these successes and one question in particular comes to mind: "how do we move from talking to doing?". I would also like to foster a feedback loop into the conferences so that the conversation has forward motion.
 My draft proposal to the community is to host a series of what I am currently calling "Open Space Coding Days". I would like these to be on a regular basis, rather like Alt.Net Beers. The focus should be on hands-on activity rather than general discussion but the Open Space philosophy still applies. Accordingly, the activities should be self-organizing. This is not about speakers or powerpoint. The only requirement we should have is to publish the code in an open repository and notes in a wiki.
My draft proposal to the community is to host a series of what I am currently calling "Open Space Coding Days". I would like these to be on a regular basis, rather like Alt.Net Beers. The focus should be on hands-on activity rather than general discussion but the Open Space philosophy still applies. Accordingly, the activities should be self-organizing. This is not about speakers or powerpoint. The only requirement we should have is to publish the code in an open repository and notes in a wiki.
Before I get tackled on the subject, for all I know this is a format that has been tried elsewhere. I suspect that the model might be very near to a BarCamp but as I haven't been to one, I don't know.
I am very interested in taking feedback. The following jump to mind but the list won't be exhaustive:
- Would you be interested in attending such an event?
- Would you or your company be interested in sponsoring?
- I have in mind to do this on Saturdays - do people think this is the right day?
- What is a reasonable number of people for a hands-on event like this (I suspect it will be fewer than for a conference)?
- How often should the event be run? Monthly? Every other month? Some other period?
- Should it run separately to Alt.Net Beers or seek to work together (perhaps planning events to coincide)?
- Is it reasonable to require attendees to bring their own laptops and have development software already installed? If not, what are the alternatives?
I am in discussions with Conchango to host the first of these as they were so supportive with our first Alt.Net UK Conference. Dates are still open as I write this.
Update (9th December)
 Conchango have kindly agreed to be venue hosts for Open Space Coding Day 1. This will be on the 31st January at their London offices.
Conchango have kindly agreed to be venue hosts for Open Space Coding Day 1. This will be on the 31st January at their London offices.
I was expecting to have to put up a reservation form, but in a flurry of tweets during today almost all of the places have been taken! Taking a leaf from Scoble, I thought I would see how effective twitter would be as an organising tool and I am very impressed! At the time of writing, there are a couple of places left. All the places have now been taken. If you wish to go on the waiting list please contact me either on twitter.com/adean or email alan.dean@gmail.com. If you can't make it on the 31st, don't worry - I will be running the event every other month, so you can always catch it next time around. People on the waiting list will be given first refusal on attending subsequent events so that there is a variation in attendees between events and that people don't feel left out. Therefore it is worth letting me know that you would like to come.
When I was at the PDC, I found it very annoying that there wasn't a consistent hashtag in use. Therefore, I would like to propose that we standardise on a single hashtag for these events. I have started using #openspacecode - the only other option that came to mind was #oscd, which (whilst shorter) just seemed too arcane to me.
Following the principle of 'golden hours', there will be two coding sessions of two hours in the day and a generous period of time for socialising over lunch:
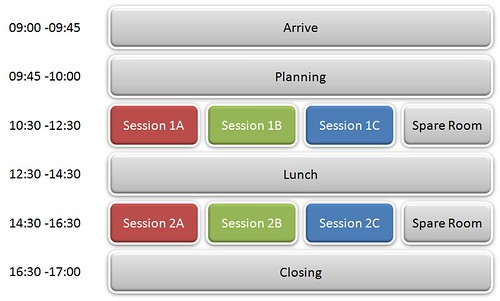
The planning process will be as follows:
- Attendees put up the sessions they are interested in having
- Attendees put their names against sessions they are willing to host. No host means the session is dropped. Be aware: the host is not a presenter, the host is not expected to even know the subject. The host is simply someone to keep the session flowing effectively for the participants.
- Attendees vote on which proposed sessions get the go-ahead.
The only exception to this process will be that I am going to try to have one 'keynote' session per event. On the 31st January, Barry Dorrans (Security MVP) has kindly agreed to host a session on "Hands-on secure development". It's certainly one session that I want to be part of!
Please remember to bring your laptop. If you don't have one, then you will have to share. There will be WiFi access available. I will be putting together trial Virtual Machines for anyone who isn't an MSDN subscriber or hasn't got Visual Studio installed. Important: if you want to propose a session using a different development environment, for example using Mono on Ubuntu, please contact me so that we can arrange a VM. These session are about doing, not presenting, and so any proposed sessions that attendees cannot participate in will be dropped before voting.
 I think that the accepted practice is to incorporate as a limited company. Certainly I can see advantages in doing so: in tax treatment and the limited liability that it offers.
I think that the accepted practice is to incorporate as a limited company. Certainly I can see advantages in doing so: in tax treatment and the limited liability that it offers.




 I have been a long-term user of
I have been a long-term user of