In two previous post ("When Basket Checkout isn't RESTful" and "What a RESTful Basket Checkout might look like") I have referred to the question of where basket state should be stored in a RESTful system. A number of conversations have ensued from these posts that I feel warrant a deeper post specifically about this question.
I will start by describing the typical basket / checkout implementation (which isn't RESTful).
The vast majority of web sites require that you authenticate (or are 'authenticated' as a new anonymous guest). A token is then passed to the client which is a reference to session state on the server. The user then browses the site, adding to the basket as they go. When the time comes to checkout, the client simply passes the token back to the server for it to retrieve the session state internally:
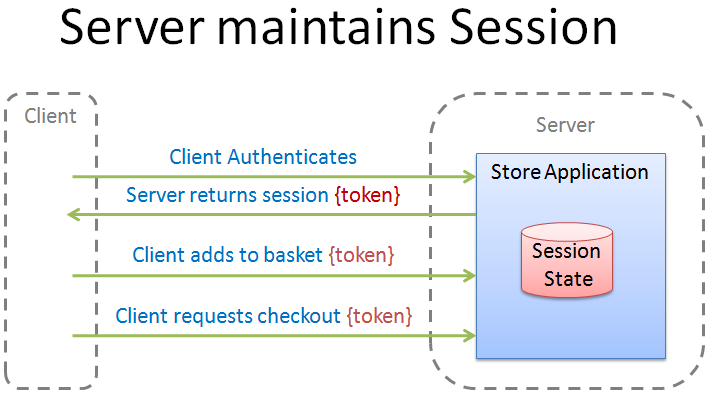
From the perspective of REST, this breaches the Statelessness constraint. From a more general perspective, the basket implementation is tightly coupled to the checkout implementation which leads to a monolithic Store Application. Serendipitous reuse is reduced or prevented. If a requirement is received to implement a rich client, for example, then either the client has to carry out site-specific work to orchestrate the basket and checkout or significant server changes must be carried out.
Moving away from this model requires that the client maintains the basket session state. For a browser, this might be in a local cookie or by using a browser extension such as Google Gears. For a rich client, this might be simply kept in memory or in a local data store. The specifics do not matter from the perspective of the client/server interactions:
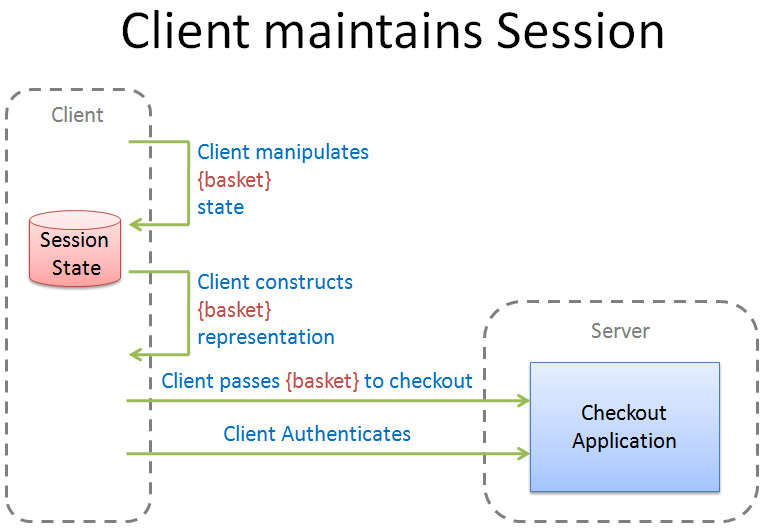
The client does not need to interact with the server until the basket is ready for checkout. Where does the client get the data to build up a basket? It doesn't matter to the Checkout Application, which is no longer monolithic. Instead it is entirely decoupled from the rest of the store. Serendipity is enhanced because clients only need to know how to construct a valid basket representation and how to authenticate. In a RESTful implementation, the basket representation will be rendered using a standardized media-type and authentication will use a standard authentication mechanism such as WWW-Authenticate.
In "What a RESTful Basket Checkout might look like" I discuss, in passing, what a RESTful implementation of basket persistence might look like. Many online stores allow the user to add an item to the basket and then to come back in 6 months time and still see the item in the basket. Alternatively, perhaps the user should be able to see the items in the basket when they use a new machine. Clearly, a RESTful implementation should allow for such functionality.
REST has a Layered System constraint. So long as this is not breached (by, for example, the checkout knowing about the basket persistence mechanism) the client is allowed to compose multiple RESTful services. In this case, the client would compose Basket Persistence with Checkout:
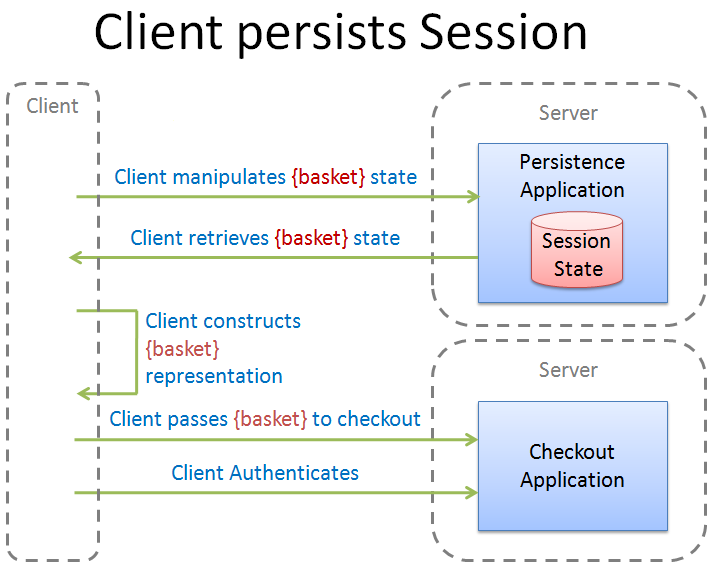
The client is free to use whichever persistence implementation is desired. Perhaps one client implementation will use Amazon S3. Another might use the data capabilities of the new Azure platform or employ a custom persistence solution. The checkout application doesn't care.
I hope that this clarifies some of the questions and answers arising from my previous posts.
10 comments:
I think I'm slowly getting it and am learning a lot from this so thanks for taking the time to do it. Seeing examples definitely makes it more clear. Too few examples and discussions of tradeoffs is one reason REST can seem inaccessible or even worse can seem ridiculously simple.
Its taking me a while to get my head around this as it jars with other descriptions of RESTful solutions to this sort of thing. For example I remember Stefan Tilkov discussing turning normal "session state" into resources on the server and giving them URLs. Once you do this you can pass those URLS around so the Checkout Application would be passed a representation including a URL to the basket representation.
I think your disagreement with that approach was the layered system constraint which is not something that I've seen discussed much, will need to read more about it. Still think it must be a valid choice if all your doing is sharing a URL though, or would you really never us it?
As you say though it wouldn't work so well in smart client situations where you might well want to create a whole basket in memory and then pass it up directly.
Very interesting stuff.
Alan:
Thanks for taking the time to post this 'walk-through.' It seems one of the key points in your example here is that the *basket* resource and the *checkout* resource are not tightly bound. This makes sense to me.
What seems to be presented here are two primary MIME-types: application/basket and application/checkout. With those two types defined, I can see a great deal of serendipitous use and a big reduction in tight binding.
Mike,
You are correct: there would be two media-types :-)
Colin,
I don't personally agree with the approach of passing a link as I feel that it has a number of difficulties. For more commentary on that, see my post "When Basket Checkout isn't RESTful".
Sorry yeah I had read it but re-reading it clarified things for me.
What confused me initially was you were referring to the basket as session (application) state, but seeing your last soluton here clears things up.
I'm wondering if this isn't the way many e-commerce sites behave in practice, just looking at the form in Amazons basket page I'm thinking you do just submit them all the items (though it is late so I could be wrong).
Also it reminds me of the push/pull thing in messaging, your recommending full messages that you push rather than the pull approach which as you say might have issues. Whats interesting is my natural inclination would certainly have been to include links to the basket, if you've got URLs why not use them.
Good stuff and thanks for taking the time to write it.
Interesting. Are you suggesting that the client maintains the basket on its own? If so, what for does it take? As some struct that the client constructs and maintains locally without any involvement from the server?
IMO, a better model is to mode the cart as a resource itself. Looking at your other post on that, I think your example for POST /checkout can be written better as
POST /checkout
Content-Type: application/checkout+xml;
<checkout>
<link href="http://.../username/basket" rel="htt://.../basket"/>
</checkout>
This is "a" representation of a resource. Here the link like a reference to another resource. If a server is ready to accept such a POST, IMO, it already implies that the server knows how to fetch the basket.
Subbu,
As I said earlier to Colin and also discussed in "When Basket Checkout isn't RESTful", I don't agree with the 'passing a link' approach.
How does the client store the basket state? However it likes. It's private state to the client. The only responsibility that the client has is to render the correct representation to pass to checkout.
If you want, the basket data being persisted by the client in the third diagram of this post "Client persists Session" could be in the basket format, so that when the time comes to checkout, the client simply GETs the representation from the persistence server and then passes that to the checkout. Nice and clean. The persistence server might even be a specialized basket store to save the client some work, but this is not required by the pattern.
Alan,
Consider the flow where the server is managing the basket as a resource:
- Client GETs a product resource.
- It has a link to add that product to a basket.
- Client follows that link to add the product the product to the basket.
- Client repeats the above steps.
- Product representations also contain a link to the basket.
- Client follows that link to view its current state.
- This representation has a link to checkout. It follows that link to do checkout.
In this model, the client does not know how to store the basket or what the internal structure of that basket might be.
On the other-hand, consider the flow when the client is managing the basket.
- Client GETs a product resource.
- Client creates a basket the first time and stores the product reference there. I am assuming that it will store the URI of the product.
- Client repeats these steps.
- Client finds a link to do checkout.
- Client POSTs the contents of its basket to do checkout.
The steps look short, but the client will be required to take more responsibilities.
More importantly, this model requires the client to know to how to compose the application and the workflow involved. In the model I am suggesting, the server provides the workflow via links. Consequently, the client remains less coupled to the server. Please see http://www.subbu.org/blog/2008/11/who-is-composing-your-app for more notes on composition.
Subbu,
My suspicion is that we are applying different preconditions to one another here.
I am applying the precondition that the basket contains generic items. Imagine a user has a shopping list of goods that they wish to purchase from a store. They can buy those goods in many different stores. The basket which describes the shopping list is not associated with any specific store.
For example, let's say that I want to buy a new Sony widescreen TV. I add the specific model I want to my basket. I can potentially purchase the basket from any one of a number of retailers.
I sense (and I accept I could be wrong in my intuition) that you have a precondition that the basket refers to items available from a specific store.
If my intuition is correct, then your approach seems to me to be more tightly coupled than mine.
I certainly agree that the checkout should be traversed by the use of HATEOAS. I didn't specify the internal behaviour of checkout in this post because it didn't seem directly relevant to the point that I was trying to make. It certainly sounds like I have another topic that I need to post about :-)
What I think that we are actually talking about here is service discovery, which is an area that has been discussed very little within the REST community (to my knowledge).
Where *does* our hypermedia start? This is an important question, not directly related to hypermedia traversal.
Alan,
You are right about my assumed preconditions.
The motivation for your approach, if I understand correctly, is to combine different servers into an app unbeknownest to any of those servers. Right?
In order to keep the client lightly coupled, I would still let each of these servers cooperate with other by using shared media types and links across servers.
It is possible to build a client without such cooperation among servers, as illustrated by your example. However, I think that such a cooperation promotes loose coupling.
To answer your last question on where does hypermedia start, it starts when a client starts interacting with an app through some URIs prepublished as starting points. In your example, the starting point may a search server that lets the client find some products. The rest of the URIs can come from the hypermedia. The paper I mentioned in my post today talks about this and other aspects related to discovery and descriptions. It should get published soon.
Post a Comment