One of the questions that has not had much discussion recently in the REST community is authentication and authorization.
Cookies should not be used by a system which is to be considered RESTful. Roy has explained why a number of times.
I have looked at both OAuth and OpenID, but they do not seem to have a good story for automated agents as they focus on having human interaction in a browser session.
What would be ideal is a standardized authentication mechanism that supports federation. The obvious candidate is HTTP Digest Authentication (the specification isn't the easiest read, I have to admit, so you might find the wikipedia entry more understandable). Granted, it doesn't have a pretty logo. But it is supported by every user agent that I know of that is HTTP-aware. What isn't clear, however, is if it can be federated to permit user agents to employ a separate Identity Provider, reducing the need for multiple online identities.
This is an itch that I have been scratching in my mind for a while and I brought it up in conversation with Steve Bjorg yesterday. This gives me a reason/excuse to post where my thoughts are on the subject right now. Please note that these thoughts may well change and I do not consider myself a security expert.
The following diagram outlines the sequence diagram that I have in mind. Important: There is a precondition that the Server already has knowledge of the location of the Identity Provider for the user. This would probably be achieved manually in the same way that OpenID does, including an 'allow access' screen.
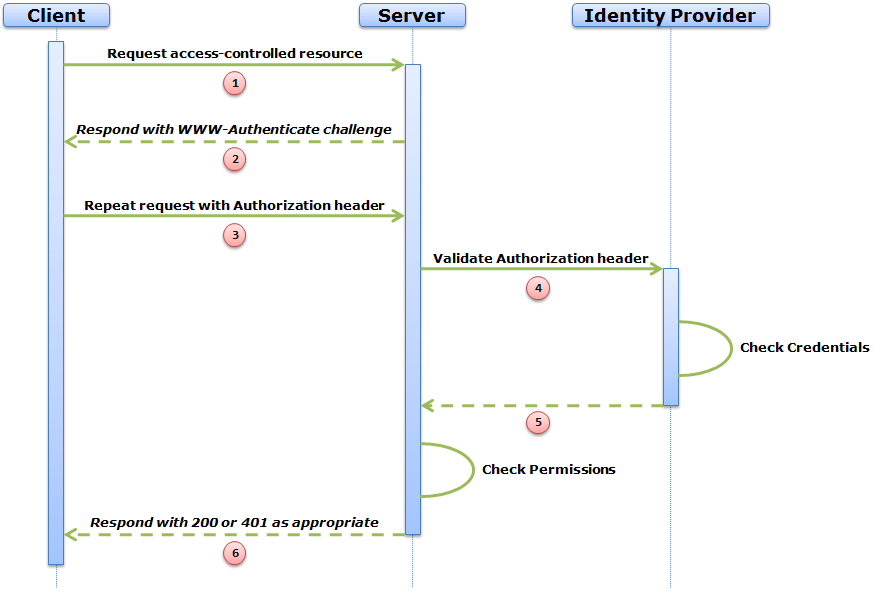
This is what the HTTP messages might look like:

The Client makes an ordinary GET request to a resource that happens to be protected.
GET /dir/index.html HTTP/1.1 |

The Server crafts a fresh WWW-Authenticate header and sends it to the Client with a 401 Unauthorized status code.
HTTP/1.1 401 Unauthorised |

The Client crafts an Authorization header by hashing the user credentials with the parameters of the WWW-Authenticate header in the normal fashion and resends the original request.
GET /dir/index.html HTTP/1.1 |

Here is the cunning part. The Authorization header contains enough information that a hash comparison can be carried out by anyone who has the correct credentials at hand. It doesn't have to be the Server. Therefore, the Server passes the Authorization header to a previously stored Identity Provider URI for validation (in this case, on http://example.org).
GET /user/Mufasa?domain=example.com HTTP/1.1 |

The Identity Provider retrieves the password of the user and performs the hash comparison. If validation fails, a 401 Unauthorized is returned to the Server. If it succeeds, a 200 OK is returned.
HTTP/1.1 200 OK |

The user is now authenticated. The Server can check permissions and respond with the representation requested, if permitted. A 403 Forbidden would be sent if the authenticated user is not permitted.
HTTP/1.1 200 OK |
There are some optimizations that could be employed. The Identity Provider could issue validation for a given period by setting the Expires header on the validation response, indicating that the Server can cache the authentication for a period. Similarly, the other conditional HTTP headers could be employed for more complex caching.
The communication between Client and Server and between Server and Identity Provider does not need to be encrypted because the credentials are always hashed on the wire, mitigating a man-in-the-middle attack.
The Client does not need to know anything about the Identity Provider. So far as the Client is concerned, this is a perfectly ordinary HTTP Digest Authentication mechanism which gives two benefits:
- There is no need for a complex set of Client HTTP requests to achieve authentication.
- The REST Layered System constraint is not violated.
I am interested to hear feedback from my audience if this is an authentication model that would be useful. As I said at the top, I am not a security expert so there may be flaws in my thinking.
16 comments:
Just to be clear, unlike OpenID or even OAuth, the user /client is providing credentials for example.com and not the identify provider. In particular, the user/client is not aware of the identity provider. Right?
If so, isn't the stuff that happens between the server (example.com) and the identity provider mere implementation detail, and it could very well do a DB lookup instead of proxying the headers to the identity provider.
I am therefore confused by the statement about "What isn't clear, however, is if it can be federated to permit user agents to employ a separate Identity Provider, reducing the need for multiple online identities." In the diagram, the user agent is not employing the separate identity provider. The server is, and that is implementation detail.
Am I missing something?
A variation would be for the client to supply the URI of an identity provider in a header. That would be quite openid like. The server just needs to determine if it trusts the identity provider.
Subbu,
My apologies - my use of language wasn't clear enough.
You are right: to the UA, the the auth counterparty is example.com and it could just have easily have got the password for validation from a local database.
To the human user (who has to associate the federated IP in the precondition step) a separate IP is being employed.
Sorry for the confusion, but you understood correctly.
Ian,
The problem with sending a new, custom, header is that no tooling out there knows how to do that. Whereas the tooling already supports plain old Digest.
The same objection holds true for any new WWW-Authenticate scheme.
There are some pretty major problems with HTTP Digest authentication, and in practice it sees very little use.
In the example you provided, the key is the ?domain=example.org parameter, which could be used with any authentication method, including OAuth. What might be interesting here is to combine OpenID with OAuth, using OpenID to say "Hi, I'm from example.org" in order to have an OAuth secret issued from example.org to example.com itself.
OpenID can be negotiated without any user intervention, assuming you have the username and password at example.org.
As for OAuth, the only step that always involves human intervention is the issuing of consumer (i.e., application) keys. In this case, you could probably get away with ignoring the consumer keys altogether (i.e., use a blank key / secret) which is definitely allowed for by the spec, and seems fitting to your example since you don't have any consumer authentication happening in the Digest example.
The other thing that you might find interesting to look at is the way that XMPP does this. Your example implicitly trusts example.org, so I think it's a fairly parallel situation to XMPP federation. Essentially, when you chat to someone at example@gmail.com, you know that they're definitely at gmail.com (unlike email or weak forms of HTTP authentication). This happens via RSA key verification or dial-back authentication.
blain,
What are the problems with Digest Auth that you refer to in passing?
Also, do you have any links to a description of the HTTP message exchange for OAuth or OpenID. None of the pages I've visited yet seem to offer a clear picture of what happens on the wire for either mechanism.
Finally, there seems to be relatively little client tooling to support OpenID or OAuth and so the audience of clients that can participate is limited, whereas HTTP Digest Auth is supported by pretty much every HTTP-aware client.
Subbu points out an important problem with your idea.
The client has given its credentials to example.com. Example.com can now use those credentials to act as the client. You present that as a feature. I suspect most security experts would call it a bug.
I would highly recommend you look at existing solutions for federated authentication, such as the Liberty Authentication Service, WS-Trust, SAML and OAuth.
John,
The client doesn't pass it's credentials to the Server (example.com). It passes a response hash.
A different server would have a different realm and would therefore require a different response hash value.
The only server that example.com can use this against is itself. Doesn't sound like much of an exploit to me.
Alan,
Regarding my previous comment, and John's comment above, I was trying to determine who the provider of credentials is? From the client's point of view, it is not the identity provider.
I would not go so far as to say that this is security bug, but this mechanism requires cooperation between these two servers. They need to share certain things, and IMO, that is an implementation detail. There is not any federation in the scenario you describe.
Subbu,
During the message exchange described above, the UA treats the Server as the IP. To that extent, the exchange isn't federated.
In global terms, however, the user identity is federated because the IP is not the Server. The easiest way to demonstrate this is that if the user changes the password stored by the IP, then all sites which employ this mechanism require the new password.
Does that clarify things?
Hi Alan,
In the case you are describing, the response hash *is* the user credentials, and that is passed to example.com. Doesn't that allow evil-example.com to ask for the same credentials, get them, and then authenticate to example.org (for some period of time) as if it were the actual client?
John,
What purpose would be served? evil-example.com would simply get a 200 OK response from the IP. That's it.
Am I missing something in your scenario? I'm not a security expert so it altogether possible that I am ;-) but I'm not seeing an exploit.
Hi Alan,
Having the nonce generated by the Server and not the IdP sounds likely to cause problems, especially with Limited Use Nonce Values. Using the next-nonce directive would at least require another interaction from Server to IdP between steps 1 and 2.
There may also be issues with the implementation of the nonce by the IdP, in particular what it checks (see RFC-2617, section 4.5).
Digest authentication already requires more requests/responses (after the first request) than basic auth. I think adding 1 or 2 (depending on nonce issue) requests to the IdP could degrade the performance substantially. Cookies might just be the way to go...
As a side note, this mechanism requires the IdP to have the password of the user stored in clear. Many authentication systems do this, but this might be a problem for some.
Other have already mentioned OAuth. For federated authentication, have you looked at Shibboleth? It requires more infrastructure, but also provides some authorisation information. It's not ideal. In particular, it will cause your non-GET requests to fail if the cookie obtained the first time has expired; it also relies on your browser allowing a transparent POST request to be made immediately after making a GET, via JavaScript. (I wrote down a list of interactions between client and server in Shibboleth, IdP excluded, if it can help.)
Bruno,
Thanks for your feedback
Firstly, as I say in paragraph 2, cookies are not in scope for this.
Secondly, My concern with the other mechanisms you mention is the paucity of tool support, whereas HTTP Digest Auth has extremely widespread support.
More than one person has mentioned OAuth (which claims RESTful support) but I haven't yet found a clear example of the message exchange (the one in the spec is scattered all over and is very hard to get a sense of, I found). Do you know of such an example?
With reference to the nonce value, I will have to do some further reading and comment on that a little later.
I'm not so concerned about perf on the basis that all authentication mechanisms are expensive. Do you know any that are cheap? (noting that cookies are out of scope)
Hi Alan,
I must admit I've never used OAuth in practice, but there seems to be a fairly good description in this Beginner’s Guide to OAuth – Part II.
I'm not sure if HTTP Digest Auth has such a widespread support, especially if you include more advanced features such as qop, etc (I don't know). Anyway, all it really protects is the password, not the content of the interactions (as other similar mechanisms, perhaps except HTTPsec).
However, I still reckon performance will be a major problem. Relying on a 3rd party for each and every request will cause a significant overhead in my opinion.
Although this might be acceptable if the IdP was sufficiently close to the Server (which is what tends to happen when using an LDAP server for example), this will be a remote bottleneck or extra point of failure if federated.
It might be worth setting up some benchmarks (preferrably with several IdPs, close and far from the Server). However, as a first guess, I'd reckon this would be slower than HTTP Basic Auth over SSL (that, however, wouldn't allow federation). Even HTTP SPNEGO auth/Kerberos first acquires tickets from the Kerberos KDC (which is remote, like the IdP), but then doesn't rely on it for every interaction. As far as I know, most secure authentication mechanisms have some form of session one way or another. I think what matters, in terms of architectural style and REST, is to make it transparent.
Now, about the cookies... Well, yes, I agree with you. It would be nice to have something without cookies for authentication (or an "authenticated session"). As far as I know, Roy Fielding's main objection regarding the use of cookies for authentication is mainly due to the fact that there's no way for the application to know the cookie is used for that purpose (in particular because it has to be treated as sensitive information).
He's got a fair point (in addition to full authority on what REST is, of course).
However, there's no mechanism to pass an authentication token similar to what such cookies do in WWW-Authenticate/Authorization in existing RFCs as far as I know. Perhaps there could be a "WWW-Authenticate: Form ..." scheme which would provide such tokens (and have support for logout, etc.), but there isn't. I'm talking about forms here because that's more or less the same problem: a short-live authentication token that can be passed back after an initial, more costly authentication operation.
Unless there's some will by user-agents and servers to support this sort of mechanism, cookies will still be widely used, even if it's incompatible with REST.
Even if I see the benefits of REST for designing web-services, cookies for authentication is something I have to do with, whether I like it or not.
Wondered if you had looked at Microsofts latest offering, Geneva and if so what you guys think of it:
http://www.davidchappell.com/blog/2008/11/introducing-geneva.html
Post a Comment